Paper : Balancing Continuous Pre-Training and Instruction Fine-Tuning: Optimizing Instruction-Following in LLMs
에 관련한 논문 리뷰입니다.
https://www.arxiv.org/abs/2410.10739
Abstract
- CPT와 instruction FT 사이의 복잡한 관련성에 대해서 파해치기
- CPT가 base model과 instruction FT model의 지시사항에 미치는 영향
따라서 본 논문은 instruction data와 FT 없이 새로운 데이터 업데이트와 instruction 수행능력을 얻을 수 있는 효율적인 방법을 찾는 것을 목표로 한다.
1. Introduction
Base Model은 주어진 시퀀스에서 다음 토큰을 예측하는 방식으로 사전 학습되어 있다. 그래서 일관된 답변을 하는 것엔 뛰어나지만 사람이 원하는 답변과는 크게 관련이 없다. 그래서 실질적인 답변을 듣기 위해 Instruction fine-tuning이 필요한 것. 해당 과정을 거친 모델은 Instruction Model이라고 부른다.
Instruction fine-tuning는 비용이 많이 들고, 라벨링 데이터도 필요하다. 그리고 모델을 최신 데이터에 맞게 업데이트 하려면 Base Model을 기존 데이터 + 새로운 데이터의 조합으로 다시 pretraining 하거나 새로운 데이터를 지속적으로 pretraining 해야한다.
그런데 지속적인 사전학습은 이전에 학습한 내용을 잃어버리는 결과를 가져오게 된다. 이를 방지하고자 여러 연구가 있었지만 지속적인 사전학습이 instruction model에 미치는 영향에 대한 연구는 진행된 바가 없다. Continuous pre-training은 새로운 지식 습득을 위해, Instruction tuning은 지시문 수행 능력을 학습하는 데 필수적이기에 이 두가지 과정이 모두 필요하다. 그랬을 때의 질문은,
- 새로운 지식을 습득하기 위해 Instruction model을 Continuous pre-training할 때 Instruction 수행능력은 어떻게 변화하는지?
- 만약 수행능력이 떨어졌다면 어떤 방식으로 instruction 수행능력을 되돌릴 수 있는지?
- Base Model의 지식 업데이트 이후에 리소스가 많이 드는 instruction fine-tuning을 추가할 필요가 있는지?
해당 논문은 위 문제를 해결하기 위해 두 가지 연구를 진행했다.
- 특정 데이터셋을 Instruction model에 Continuous pre-training하고, EleutherAI의 LLM harness framework로 성능 관찰
- 1번 연구와 동일한 데이터로 base model을 Continuous pre-training하고 instruction fine-tuning 하기
-> 위 2가지 설정으로 만들어진 Instruction model의 Instruction 수행능력 비교
instruction fine-tuning이 비용이 많이 드는 작업이라 base model의 instruction fine-tuning model이 있는 경우 Continuous pre-training model의 instruction 능력을 되찾는 간단하고 효율적인 접근법을 발견했다. 아래 4번에서 구체적으로 설명되어 있다. 이 연구는 Llama3, 3.1, Qwen2, 2.5 같이 계열의 모델 간의 instruction 수행능력 이식 가능성을 발견한 최초 연구이다.
2. Background
Base model과 Instruction model이 모두 공개가 되어있는 LLM 계열에 중점을 두고 시작한다.

위와 같은 상태에서의 목표는 다음 두가지 특정을 모두 가진 d2 데이터 특화 LLM이다.
- P1 : d2는 d1에 비해 크지 않으므로 처음 pretraining한 base model이 얻은 언어 이해능력을 잊지 않도록 하기.
(d2는 7B 정도 규모의 LLM이 필요한 이해능력을 얻기엔 부족한 크기 < 1B Token ) - P2 : 결과 model이 인간의 요구에 맞는 텍스트를 생성할 수 있도록 base model과 동일한 수준 이상의 instruction 수행능력을 갖춰야함.
위 두 가지 특성을 적용하기 위해 다음 설정 필요
- S1 : Instruction Tuned된 LLM 으로 시작해서 d2 를 이용해 CPT 한 결과 LLM이 P1과 P2를 가지도록 하는 방법
- S2 : Base model 을 d2으로 CPT 하여 d1에서 학습한 내용을 잊지 않도록 하고 (P1 획득), 그 후 v1를 사용해 instruction 수행능력을 얻는 instruction FT 적용 (P2 획득)
2.1 Resulted LLM
2.1.1 Setting 1 : Instruction-Tuned LLM의 CPT
d2로 CPT해도 instruction-Tuned LLM의 instruction 수행능력을 잃지 않을 것이다라는 가정 하에, Setting 1은 새로운 지식과 Instruction 수행능력을 동시에 얻을 수 있는 방법 중 가장 비용이 적게드는 방법이다. 하지만 실험 결과 해당 가정을 입증할 증거를 찾기 못했고 오히려 가정이 틀렸다는 것을 알게됐다.

2.1.2 Setting 2 : Base LLM의 CPT 후 Instruction FT
이 설정에서는 먼저 base model을 d2으로 CPT하여 새로운 base model 을 생성한다. 이 모델은 새로운 도메인 지식을 학습하되, 초기 학습된 지식을 잃어버리지 않는다. 이제 instruction 수행능력을 추가하기 위해 새로운 base model을 instruction tuning 해야한다.

Instruction tuning을 진행하려면 고품질의 형식화된 데이터를 수집/구성 한 후 supervied learning으로 학습하고 FT 해야한다. 그런데 이 방식은 시간과 비용이 많이 들어가고 깨끗한 데이터 확보, 최적화 등 어려움이 많다. 만약 원본 instruction FT 데이터셋이 있다면 일부는 해결가능하지만 FT 안정성같은 문제는 여전히 남아있다.
2.2 Instruction Residuals (지시문 잔차)
Instruction 수행능력을 되돌리기 위해 instruction residuals에 대해 설명한다. 파라미터에서 instruction LLM인 d1v2에서 base model d1의 잔차를 아래와 같이 계산한다.
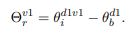
위 계산법은 LoRA, QLoRA, DoRA 같은 파라미터 효율적 LLM FT에서 영감을 받았다. 이 기법은 주어진 계층에 대해 큰 가중치 행렬 W를 FT 하는 방법 대신 새 정보를 원래 모델에 통합할 저랭크 ΔW 행렬을 학습하여 Wupdated = W + ∆W 로 한다. ΔW에 의해서 적은 파라미터로 원래 모델에 새로운 새 지식을 추가할 수 있다. ΔW의 rank가 높아지면 전체 모델을 모두 FT 하는 것과 유사해진다.
이 새로운 기능을 학습하기 위해 가중치를 추가하는 아이디어에서 영감을 받아, 먼저 instruction-tuned LLM 가중치에서 base LLM 가중치를 빼는 방식으로 지시문 튜닝된 instriction 수행 능력을 추출한다. 이를 instruction residuals 라고 하고 이 잔차를 d2으로 CPT된 base LLM에 추가한다.

여기서 Θrv1는 요소별 덧셈을 나타낸다. 이런 텐서 덧셈과 뺄셈을 통해서 instruction 수행능력을 되찾는 방법은 계산비용을 줄이는 방법이기에 새로운 지식이 base LLM에 학습되면 instruction-Tuned LLM을 쉽게 사용 가능하다. 이 연구의 제한 사항으로 만약 base LLM과 이에 대응하는 instruction-Tuned LLM이 존재하지 않으면 잔차방식을 사용할 수가 없어서 이때는 수행능력을 되찾기 위해 FT 과정이 필요하다.
3. Experiments
3.1 Dataset
3.1.1 Pre-training Dataset
Continuous pre-training model이 Instruction 수행능력에 미치는 영향을 보기 위한 사전 학습 데이터셋이 필요하다. 데이터는 base model에게 던지지 않은 데이터를 사용해야한다. 오염된 데이터를 최대한 피하기 위해 FUNDUS5라는 뉴스 크롤러를 사용하여 약 200만개의 기사를 수동으로 수집했다. Llama3.1에 학습되지 않은 데이터를 모으기 위해 2023년 12월을 기점으로 뉴스를 수집했고 기사 평균길이는 650 토큰 (최대 6,981 토큰 최소 156 토큰)이다.시퀀스 길이는 4096(최대 8K인데 기존 GPU vRAM 효율성을 위해서 4K로만) 패킹했다. Kosec et al. (2021)와 비슷하게 주의 분산하는 마스크 사용해서 기사간 오염 최소화 시켰다.
3.1.2 Evaluation Dataset
평가하기 위한 테스트 데이터셋. MMLU, MMLU-Pro, GSM8K는 5샷 평가로 수행되었고, 나머지 데이터셋은 제로샷 평가로 수행되었다.

- Instruction 수행
- IFEval: 이 데이터셋은 LLM의 자연어 지시문 수행 능력에 초점을 맞추기 위해 도입. 500개의 프롬프트와 400단어 이상의 작성을 요구하거나 AI 키워드를 최소 3번 언급하도록 하는 25가지 검증 가능한 지시문을 포함함.
- MMLU: 수학, 컴퓨터 과학, 의학, 철학, 법률 등 주요 분야를 포함한 57개 과목의 광범위한 세계 지식에 중점을 둠. 총 15908개의 개발 및 테스트 질문이 있으며, 각각 4개의 가능한 답변을 포함
- MMLU-Pro: 기존의 LLM이 MMLU에서 뛰어난 성능을 보이기 때문에 MMLU 벤치마크의 복잡성을 높이기 위해 도입. MMLU에서 사소하고 노이즈가 있는 질문을 제거하고, 주로 지식 기반 질문인 MMLU에 추론 중심 질문을 추가해 구성.
- GSM8K: 언어적으로 다양한 초등학교 수준의 8.5K 고품질 수학 문제로 구성. 문제를 해결하는 데 2~8단계가 필요하며, 주로 기본 산술 연산(+, −, ×, ÷)을 사용하여 순차적인 계산을 수행.
- 추론 및 문제 해결
- Winogrande: 대규모 44k 상식 추론 데이터셋으로, 맥락 이해를 바탕으로 모호한 대명사를 해석하는 모델의 능력을 테스트.
- Hellaswag: AI 모델의 상식 추론을 벤치마크하기 위해 설계됨. 주어진 상황의 가장 그럴듯한 결말을 예측하는 10,000개의 다중 선택 질문을 포함함.
- ARC_easy: 7787개의 자연 과학 질문으로 구성된 데이터셋. 주로 자연스럽고 초등학교 수준의 과학 질문을 포함하며, 다양한 지식 및 추론 스타일에 초점을 둠.
- Piqa: 모델을 물리적 상식 질문으로 평가. 각 지시문에는 물리적 환경 설명과 함께 목표가 주어지며, 목표를 달성할 수 있는 2개의 옵션(해결책)이 제시되어 있다.
- Truthfulness: 언어 모델이 질문에 대한 진실성을 측정하는 데이터셋. 건강, 법률, 금융, 정치 등 38개의 범주에 걸쳐 817개의 질문으로 구성되어 있으며, 인간의 오해, 허위 신념, 음모론, 현실 세계 지식과 허구적 지식 간의 인식을 포착함.
3.2 Language Model Architecture
논문은 Llama와 Qwen 모델을 사용했다. 사용된 모델은 다음과 같다
| 모델 버전 |
사용 가능한 파라미터 크기 |
| Llama3 | 8B, 70B |
| Llama3.1 | 8B, 70B, 405B |
| Qwen 2 | 0.5B, 1.5B, 7B |
| Qwen 2.5 | 0.5B, 1.5B, 7B, 3B, 14B, 32B, 72B |
→ Llama 계열 : 리소스 제약으로 8B 모델만 사용
→ Qwen 계열 : 0.5B, 1.5B, 7B 모델 사용
4. Results and Analysis
Continuous pre-training 했을 때 Base model과 instruction model의 수행능력에 미치는 영향에 대한 분석 결과이다. 새로운 지식으로 학습한 모델이 FT이 필요한지 여부를 판단하고, 업데이트된 LLM의 손실된 정보에 대해서 FT 없이 수행 능력을 복원하는 instruction residuals 에 대해서 평가한다.
4.1 Continual Pretraining 영향

CPT 영향을 평가하기 위해 Llama3 8B 모델인 Llama3 intructions-tuned (L3i), Llama3 base (L3b)을 사용하고, 새로운 토큰의 양이 수행능력에 미치는 영향을 보기 위해 100M, 500M, 1B 양의 토큰을 사용하여 CPT 진행.
위 표의 (A)를 보면 L3i는 새로운 토큰의 양이 늘어날수록 수행능력 감소하고 L3b은 새로운 토큰을 늘려도 영향도가 크지 않다. 따라서 base model은 새로운 토큰이 추가돼도 상대적으로 안정적인 성능을 유지하고, instruction model은 많은 양의 새로운 토큰으로 CPT를 진행하면 손실의 크기가 커진다는것을 확인할 수 있다.
4.2 Instruction 수행능력 복원

위 2에서 CPT된 base model에 instruction residuals인 Θrv1를 추가해서 instruction 수행능력을 되찾았다.

위 표(Table 2)에서 instruction residuals 기법을 적용했을 때 모델 성능이 크게 향상되고 있음을 보여준다. 잔차 조정 모델(L3b + 3Lr)를 500M 토큰으로 pre-training 했을 때 모든 부분에서 L3i보다 평균 4 point 정도 높은 성능을 보인다. 토큰 수가 증가할수록 성능은 더 높아지는데 1B의 새 토큰을 pre-training 했을 때는 평균 5 point의 높은 성능을 보였다.
해당 결과를 바탕으로 instruction-Tuned model의 지식을 업데이트 한 후 추가적인 instruction-FT이 필요하다는 점을 확인했다. 또한 Instruction residuals 는 CPT의 instruction의 수행능력을 복원할 뿐만 아니라 다양한 작업에서 능력을 향상시킨다는 것을 알 수 있다.
4.3 LLM 계열 간 instruction 이식성
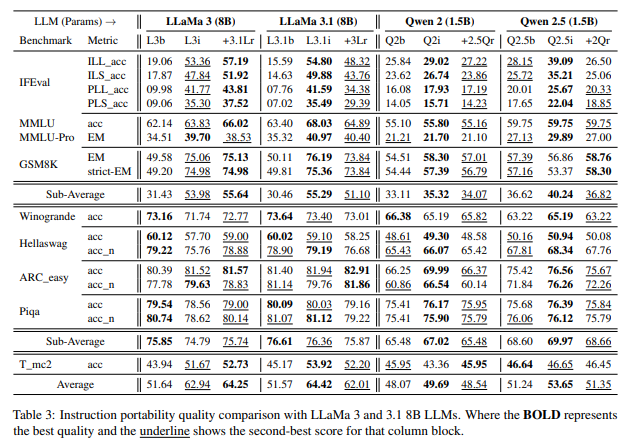
위 표(Table 3)에서 다양한 크기의 모델에서 instruction residuals 영향에 대해 보여준다. 표에서 예로, +3.1Lr은 Llama3.1 계열의 instruction residuals을 Llama3 base model에 추가한 것을 의미한다.
Llama 계열에서 instruction residuals가 항상 base model의 instruction 수행능력을 향상시키는 것으로 나타났다. Llama3과 3.1 모두 모든 데이터셋에 대해 base model 대비 성능이 향상됐다. Llama3.1의 기술 보고사에 따르면 Llama3.1이 품질이 높은 instruction 수행능력을 갖추고 있어 Llama3.1의 instruction residuals가 Llama3의 instruction residuals보다 더 나은 수행능력을 가지고 있다는 것으로 예상된다. 표에서도 Llama3.1 + 3 residual 보다 Llama3 + 3.1 residual 한 성능이 더 우수했다. 이 실험에서 눈에 띄는 점은 instruction residuals가 있는 모델이 항상 해당 base model보다 성능이 우수하다는 것이다. 이로써 동일 계열 모델간의 instruction 수행능력 이식 가능함을 입증했다.
4.4 파생된 LLM에 대한 instructions residuals 적용가능성
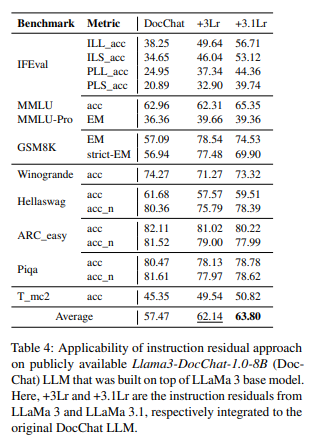
HuggingFace를 통해 Llama3에서 파생된 모델 중 cerebras/Llama3-DocChat-1.0-8B 모델을 실험 대상으로 선택했다. 실험 결과 Llama3과 3.1 모두 instruction 수행능력을 상당히 향상시켰음을 알 수 있다. 이를 통해서 instruction residuals 가 동일한 계열 모델간에 이식 가능함을 입증했다.
5. Related Work
Continual Learning 기법은 최신 정보 업데이트를 했을 때 이전 학습에서 습득한 지식을 유지하면서 새로운 데이터에 적응할 수 있도록 하는 잘 확립된 기법이다. 하지만 이 기법은 LLM에서 새로운 지식과 instruction 수행능력을 동시에 습득하는데 효과적이라고 입증할만한 충분한 연구가 이루어지지 않았다.
Model Merging 기법은 특화된 FT 모델을 병합하는 기법으로 기능을 결합할 수 있음을 보여준다. 여러 merge 기술이 instruction 수행능력 전이에 미치는 영향은 다를 수 있다. 본 논문의 연구 범위와는 벗어난다.
6. Conclusion
본 연구는 base 및 instruction-tuned LLM의 CPT와 instruction 수행능력에 미치는 영향에 대해 조사를 했다. 그 결과 instruction model의 CPT는 instruction 수행능력을 잃게 할 수 있으나, base model을 새로운 데이터로 CPT 한 후 instruction tuning을 수행하는 것이 더 효율적이라는 것을 시사한다. 이 방법은 도메인 지식과 instruction 수행능력을 모두 보존한다. 또한 본 연구를 통해 instruction 수행능력이 동일한 계열 모델 간에 전이 가능하다는 점도 밝혀내, CPT된 base model에 대해 추가적인 instruction tuning이 필요하지 않음을 보였다. 이 분석은 Llama 계열 모델에서 입증됐다.
Limitations
본 연구는 80억개의 파라미터를 가진 모델에서 검증이 됐고, 15억개 정도 되는 작은 모델에서는 결과가 현저히 달라짐을 관찰했다. 특히 1.5억 파라미터 미만의 모델에서는 해당 연구의 전략을 사용하기 어렵다. 따라서 작은 모델에서도 동일한 수준의 성능을 유지할 수 있는 추가적인 연구도 필요하다.
Instruction residuals 기법에서 중요한 과제는 base model과 instruction FT model이 모두 필요하다는 점이다. 두 모델 간의 잔차 차이에 크게 반응하기 때문에 둘 중 하나라도 없으면 사용이 불가능하다. 만약 리소스나 계산 능력 부족으로 두 모델을 동시에 보유한 상태로 활용하기 어렵다면 해당 기법은 사용이 어렵거나 병목 현상이 발생할 수 있다.
요약
- instruction model을 CPT 하는 것은 수행능력을 저하시킨다. (4.1)
- CPT된 base model에 instruction-tuning을 적용하면 도메인 지식과 instruction 수행능력 모두 유지된다. (4.4)
- 동일 모델 계열 간 instruction 수행능력 이식 가능하다. (4.3)
- CPT된 base model에는 instruction-tuning이 필요하지 않는 대신 instruction 수행능력을 이식할 수 있다. (4.2)
- Instruction residuals은 base model과 instruction FT model 모두 있을 때만 가능한 방법이고 파라미터 크기가 15억개 이하일 때는 권장하지 않는다.